I had been working with Elm for more than two years. I was new to the language and statically typed functional programming too. I mainly come from a dynamically typed programming background (JavaScript, Python) but I had functional programming experience through Emacs Lisp. Hereby I’m collecting my insights and lessons learned. Since Elm is not only a language, but also a runtime and a framework, I will cover these aspects respectively.
Language and compiler
I have to admit that it took some time until I got used to the syntax of the language. (I had no prior experience with ML languages.) Eventually I find Elm’s syntax very clear and explicit, and now I love it. Especially after working with TypeScript. With help of elm-format, there’s even one preferable way to write Elm code.
One of the first surprises was that partial application is not only a feature you may use. Partial application is part of the core language. All Elm functions take only argument and return a function with the rest of the arguments. Therefore syntax-wise, there’s no difference between defining a constant value or a function that takes no parameters. It makes things so simple!
It’s liberating how safe and fun is to do refactoring an Elm code base. Static typing combined with Maybe, pattern matching, and Elm’s friendly compiler messages are incredibly helpful. Change the name of a binding or a function’s type signature, and the compiler will tell you exactly what you need to correct. (Almost on a par with Haskell’s type-hole feature.) Introduce a new type value for a custom type and the compiler will let you know of unhandled cases. No more guard conditions to make sure you access the value you assumed. No more unit tests to make sure you handle invalid input cases. When refactoring becomes this easy, improving code design becomes habitual.
I remember I initially struggled a bit with the Maybe type. It was annoying that I need to handle all the possible cases of absent data (sic!). Now I find it a powerful tool for explicitly stating if a certain value can be missing, and the compiler will force you to handle that case. No more Cannot read property ‘context’ of undefined errors in production and such. (Interestingly, when it comes to certain data types, such as List, that have already an empty value, the type Maybe List offers two blank states: Nothing and []. In this case, it’s recommended to use custom union types to be more expressive.)
Type aliases provide an elegant way to reuse existing types and give them a more meaningful name in the given context. However, when it comes to record IDs, they are often best described as custom types. This way the compiler can make sure that only the right type of value can be passed around. Furthermore, opaque types also advocate an API that doesn’t expose implementation details.
Architecture and runtime
Elm is not only a language, but also a very opinionated architecture that was designed to build webapps with. Think of it as TypeScript, React and Redux bundled together. In fact TEA, The Elm Architecture, inspired frameworks such as Redux. TEA is simple, straight-forward with no hidden magic. Regardless of the complexity of the web app, it all boils down to a Model data record, an init, update and view function. Therefore there’s only one way to build a web app with Elm.
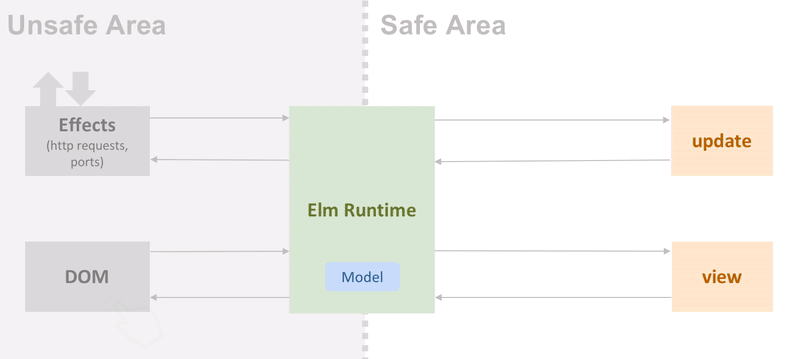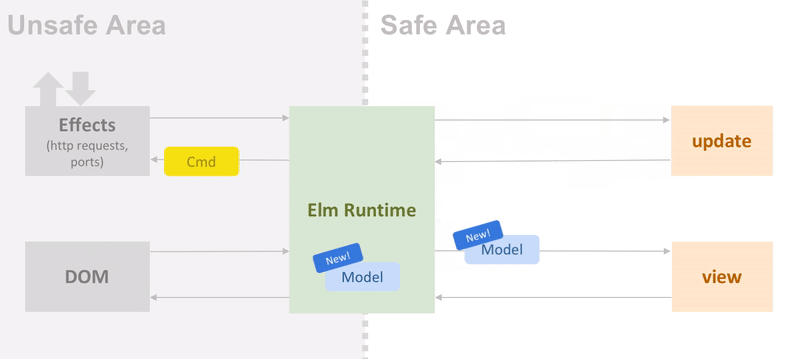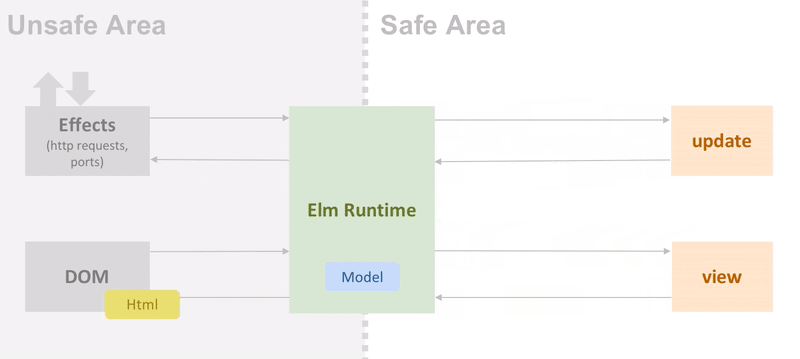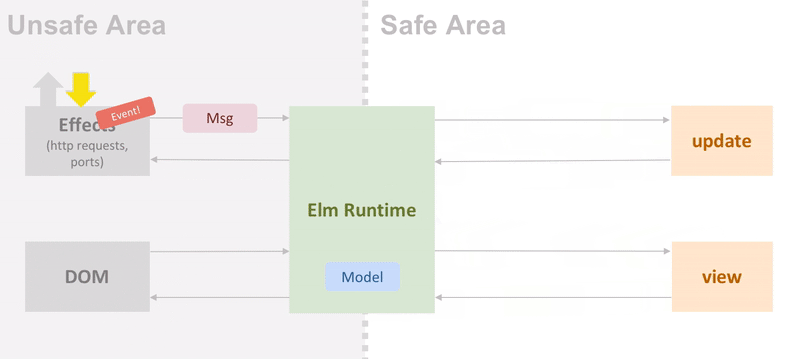
Elm is a purely functional language. Elm user-space functions have no side-effects. Interactions with the outer world (such as sending a HTTP request) are wrapped in the opaque type Cmd that is then passed to the Elm runtime. When there’s a response available, the runtime will call the program’s update function with the appropriate message. This model is extremely powerful and guarantees type safety in the entire program.
While there is a strict convention to follow for an Elm app’s architecture, there’s plenty of room space to decide how to tackle internal application complexity. A conclusion that I arrived a bit late was to keep the sub component’s signature as close to Browser.element, Browser.application as possible and use the effect pattern to abstract away Cmds, and therefore make the application testable by elm-program-test.
The articles If you’re using React, Redux and TypeScript, you would be so happy with Elm! and React Redux Thunk vs Elm are two helpful comparisons of Elm and an equivalent JavaScript stack.
Code organization
Everyone carries code organization and refactoring best practices they picked up in the past. However, they aren’t necessarily meaningful in Elm. The official guide suggests to focus on finding the right types and data structure first to describe the problem, and worry about file size later. Organize your code around types, not components or the MVC pattern. As I mentioned before, in the end of the day what you need to provide is a single Model record and the update and view functions.
In his talk The life of a file, Evan Czaplicki shows his approach of figuring out when to split code. He illustrates the problem with two checklists that would give the idea for many of abstracting away a checkbox list component. While implementing the business logic, it turns out that eventually there’s very little in common between the two solutions and early abstraction would have lead to poorer code design.
Alex Korban, author of the book Practical Elm, also shares his take on code organization. He points out that “you are still ultimately passing a single update function and a single view function to Html.program” when working with the Elm architecture.
Finally, Richard Feldman, author of elm-spa-example, demonstrates different refactoring techniques that come handy as your code base grows. He discusses narrowing responsibilities on various levels.
Learning Elm changed how I work as a programmer. I model the problem with types first, and then basically the implementation just follows along. Make impossible states impossible is my every day mantra even when working with other languages. But here’s the thing: Elm really helps you to map out all the state transitions. Pattern matching is the main tool to achieve this. Elm too supports a catchall pattern like in other languages however I learned to avoid it whenever possible. Without a fallback case, whenever I introduce new type values, the Elm compiler will tell me to handle the missing branches. This gives me an opportunity to revisit all the places where I might need to add a new business logic, instead of just silently doing the fallback action. This approach, however, might result in lots of code. That’s another thing I learned no to be afraid of. It’s lots of code but because it’s incredibly explicit. One of the most common complaints about an Elm code base is that it’s too verbose. I believe the right way to handle this in the Elm world is via code generation. I didn’t have a chance to work with it.
Finally, thanks to the Elm language server, should you use Emacs or VSCode, you get IntelliSense and all the bells and whistles you might need. However the biggest aid is still the language and the Elm compiler itself. Thanks to that, it’s possible to have tools such as the elm-review that can remove dead code automatically and safely.
Learning resources
There are many great resources available to study Elm.
- Beginning Elm: a gentle introduction to Elm programming language, a book by Pawan Poudel, is freely available online
- Programming Elm: Build Safe and Maintainable Front-End Applications, a book by Jeremy Fairbank, for those who prefer the classic format
- Elm Weekly, a newsletter by Alex Korban, a source for the news from the Elm ecosystem and further study materials as well
- Elm Patterns, a collection of design patterns for Elm
- Elm Radio Podcast, a weekly discourse on functional programming with Elm, my go-to-channel to learn about Elm
The Zen of Elm
Inspired by The Zen of Python, I compiled a verse of patterns and best practices in Elm.
- Narrow is better than broad.
- Modules should be built around a central type.
- Parse, Don’t Validate.
- Wrap early, unwrap late.
- Opaque is better than transparent.
- Maybe is better than blank.
- Although a custom type might be better than nothing.
- Make impossible states impossible.
- Unhandled cases should never pass silently.
- There should be one – and preferably only one – obvious way to write it.
- Always prefer qualified names.
- Use custom types for record IDs.
- Data structure should be the last argument of a function.